Data Synchronization Overview¶
EnOS™ Data Synchronization service supports the synchronizing of data between extensive heterogeneous data sources, helping data developers with the following tasks.
- Synchronizing data: Synchronizing structured data from external source databases to the Hive Library in EnOS and from EnOS Hive to external target databases.
- Synchronizing files: Synchronizing files from external source databases to the EnOS HDFS file storage (currently supporting Azure Blob data source).
A data synchronization workflow is a specific type of workflow and its essence lies in that it is a workflow that contains a single data synchronization task, as shown in the figure below.

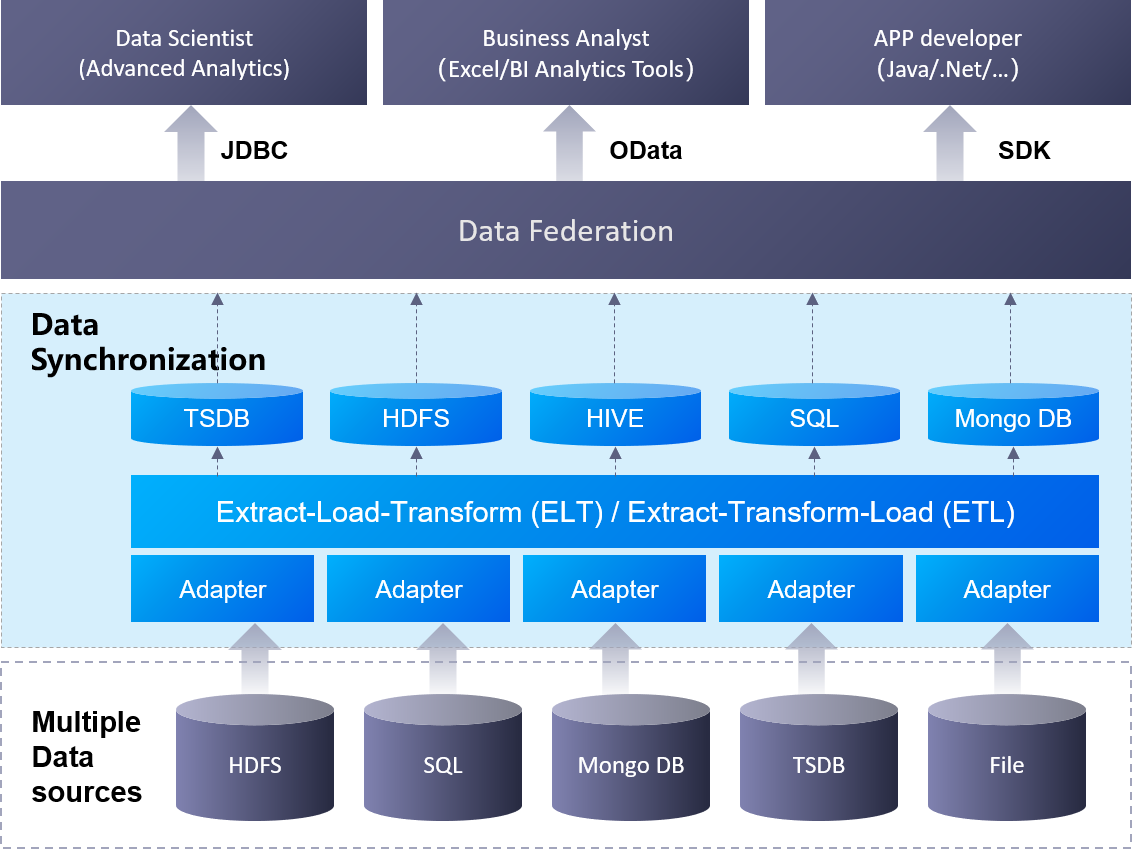
The major components and architecture of the Data Synchronization service is shown in the figure below.
Usage Scenarios¶
The typical scenarios of data synchronization are as follows.
Full-load Data Synchronization¶
The synchronization of full-load data usually happens at the initial stage of data synchronization where you can synchronize the full-load data from the data source just once. For more information on how to do this, see Synchronizing Data from External Data Source to Hive (Manaual Scheduling).
Incremental Data Synchronization¶
The synchronization of incremental data usually happens after the initial stage, when you only want to synchronize the new or updated data periodically. In this scenario, you can select the incremental data to synchronize via a where clause when you configure the synchronization workflow. For more information on how to do this, see Synchronizing Data from External Data Source to Hive (Periodic Scheduling).
Synchronizing Files from External Database to HDFS¶
For more information on how to do this, see Synchronizing Files from External Databases to HDFS.
Supported Data Source Version¶
The versions of data sources that are supported by the Data Synchronization service are as follows:
| 数据源 | 版本 |
|---|---|
| MYSQL | 8.0.16 |
| Redis | 3.0.1 |
| GitLab | 4.1.0 |
| SQL Server | 4.0 |
| S3 | 1.11.608 |
| BLOB | 8.0.0 |
| ORACLE | 10.2.0.4.0 |
| Mongo DB | 3.12.7 |
| FTP / SFTP | N/A |
| PostgreSQL | 42.2.8 |
Resource Preparation¶
Before using the data synchronization service, you need to have the following computing and storage resources.
- Batch Processing (Queue and Container): For configuring and running data synchronization tasks, and processing offline data with hive and spark.
- Data Warehouse Storage: For running offline data analysis tasks, creating Hive tables, and writing data to Hive tables.
- File Storage HDFS: For running offline data analysis tasks and storing files to HDFS storage.
Ensure that your OU has requested for the needed resources through the EnOS Management Console > Resource Management > Resource List page based on your businees needs. For more information about requesting for resources, see Resource Specifications.
When you do not need to synchronize data or files with the Data Synchronization service, you can delete and release the requested resources through the Resource Management page to save costs.